Merry christmas everyone!
It’s been a (very) busy year on my end and I’ve barely got any time for myself to post. I actually had things to talk about, like a small Nintendo Switch research paper that I published or some very specialized Z/2Z polynomial factoring code that I wrote but most of my articles just kinda went on the backburner. I have more than 10 in a draft status now!
But that’s not what we care about today because today I went back to Kingdom
Hearts 2. Again.
I time-limited myself to a week this time around though because I ain’t crazy enough to go back into
this rabbit hole but you don’t have to take my word on it, you can read back my
article on how I reverse engineered KH2’s 3D Model
format or simply the reaction of
people modding the game when I announced my project.
Pretty self explanatory
Small note to the interested readers: I won’t make a line-of-code per line-of-code explanation of my thought process along with how to write loaders/analyzers/whatever in this post. For this I encourage you to read my code, Ghidra’s own source code, the Ghidra API help or anything implementing a feature that looks like what you want. This is by far the fastest and easiest way to implement something, compared to a streamlined tutorial made for my own needs.
Kingdom Hearts 2 architecture
So, KH2 is an odd one when it comes to game development. Everything built for it
is custom, and it encompasses absolutely everything, from the higher level
packing archives to the 3D Model formats alongside its own texture and music
format including, of course, a custom AI assembly-like language.
Multiply this to the PlayStation 2 architecture and the size of the game and you
get a one of a kind experience that only gets worse the more time you put into
it.
So today’s goal was to reverse engineer the AI, as I said a billion times already. It is the biggest format with no tools being even remotely near to be able to parse or mod the format, and as such is a pretty funny challenge, along with its weird design choices that you’ll see in a bit.
The first thing to do in that case is to trace the memory usage of the game
through a debugger and break whenever the AI is read from or written to.
Eventually you’ll end up in the interpreter loop 0x1da558 in KH2FM, which you can see a part of
below:
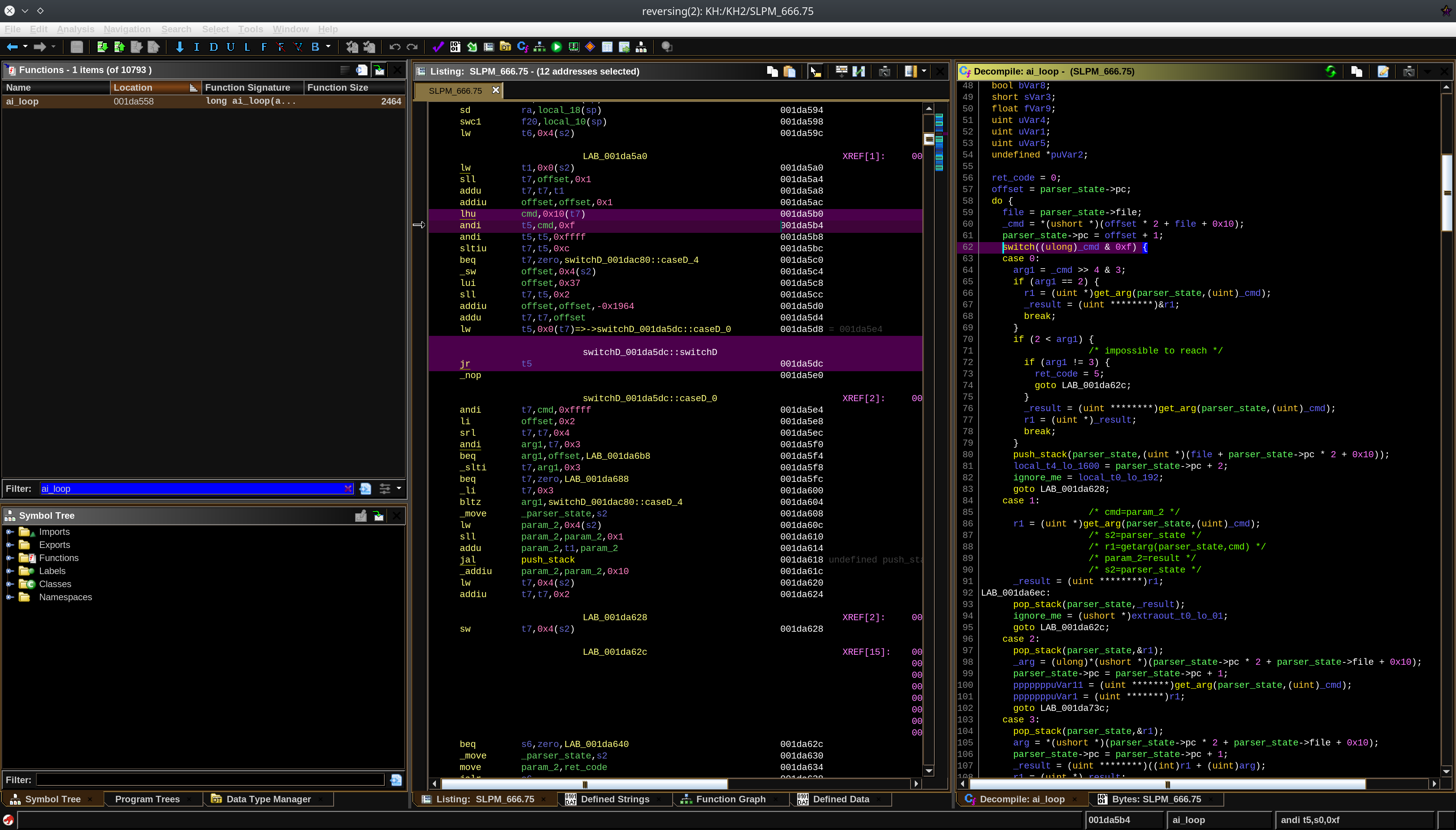
KH2 AI Interpreter
The first thing I realized from this interpreter is that the language is using Variable Length Encoding(VLE) and is very much assembly-like, but that isn’t to say it’s your average assembly, it has some… peculiar design choices. Kingdom Hearts 2 implement what’s known as a Compare and Modify(CAM) language, akin to FORTH, which is just a fancy name to state that there is no actual control flow in this AI, everything that’s done being modifying the stack, and the return adress not being on the stack. If you know anything about assembly, you must have control flow somewhere otherwise you’ll always end up executing the same thing, which isn’t great for our use case.
The way KH2 does this is by using syscalls. A lot of them. Each syscall eats up all the stack and handles itself the control flow. That doesn’t mean the language itself doesn’t have conditionals though. Let us take for example the command neqz, which pops the last value from the stack and returns the result of the expression (value != 0). This is then used by a syscall to decide which code path it should take.
Other than the CAM design, other odd choices include the commands push.c and
push.ca which, basically, do the same thing in a different manner, or even
encoding trigonometry operations in the same opcode as the exit and return
ones(!!!!!!). You also have great instructions such as pop.l, which pops a stack
value at a relocated address inside the AI’s own region. I guess it’s your goto
instruction if you want self-modifying code? It’s never used in practice. At
least they somwhat make use of the PS2 co-processors(COP0-2) to speed up that
thing.
It’s what I’d call a “hot mess” but also a funny experience at language design: after all it somehow
worked.
Moving on, now that we roughly know what we’re getting into, it’s time to move on to actually implementing all of that knowledge into something usable, and for that I’ll have to fanboy for a bit.
Ghidra architecture
Ghidra is an amazing piece of technology. I was really skeptical when it first
came out, but it turned out to become my main reversing tool almost directly for
multiple reasons, the first being SLEIGH.
SLEIGH is really two languages into one: a bitflag en/decoder, allowing you to
easily define instructions patterns and allowing them to be decoded and encoded
easily, and an instruction behaviour specificator, which tells how an
instruction behaves at a higher level. This already is a breath of fresh air
when it comes to other available tools, especially since Ghidra is able to mesh
up together a decompiler based on this specification. Added to that includes a
project and collaborative project management system which are really welcome, a
quick scripting AND an extension system that ends up being very powerful in
their own ways, along with the entire software being designed as a framework,
and not as a monolithic tool, with design choices making it much easier to work
with.
Add on to that the open source nature of the project and its analyzer design and
this is a win all around for me.
Processor definition
Going back on tracks, this is perfect for our use case as a single SLEIGH
definition allows us to produce a working assembler, disassembler and decompiler
without having to have a new codebase for each project. So that’s obviously
where I started.
SLEIGH’s file format is rather simple, but there is a code highlighter/syntax
verifier et al available for the eclipse IDE if you want, which can be ported to
vim with some tinkering. I learned about it fairly late and did not bother
installing it on my side, so it can definitely be done without it.
I’m not going to detail this as there is plenty of code examples about this including, well, my own codebase, so I’ll talk about what I did next: documentation.
Ghidra has this nifty feature of being able to open up the processor manual at the correct page by right-clicking an instruction. I wanted to make use of that, knowing very well no people that will use my tool will read my sleigh files. So I made my own LaTeX classes for an ISA manual. And it’s ~70 pages long. I even made custom “sleigh parsers” to extract sleigh code related to each instruction and build it in the manual to document what each operation does. Cool beans.

KH2AI ISA Manual by yours truly
File Loader
We have some sort of a processor definition done now so it’s about time to make
a file format parser!
You have two main ways to extend Ghidra: extensions and scripts.
Scripts are easier to develop, can be written in python and can be executed on
the fly on anything you’re working with. This made it a first choice to me when
it came down to making something quick that works(TM). With that said scripts
are a small amount more annoying to run than extensions and are not as
extensible when it comes down to adding new features into Ghidra and as such I
decided to move to extensions after a bit. The move was mostly motivated by
something I’ll explain in the next section but also by the extension design:
indeed, by more extensible what I mean is that extensions are basically java
objects hotplugging into Ghidra’s code at loading time and rewriting some of its
features. You are literally rewriting Ghidra’s own code at runtime, which I
absolutely love design wise.
What this swap meant for the project was the ability to auto-detect KH2 AI files
and loading them automatically, as opposed to opening a blank window and running
a script, along with better file format labelling.
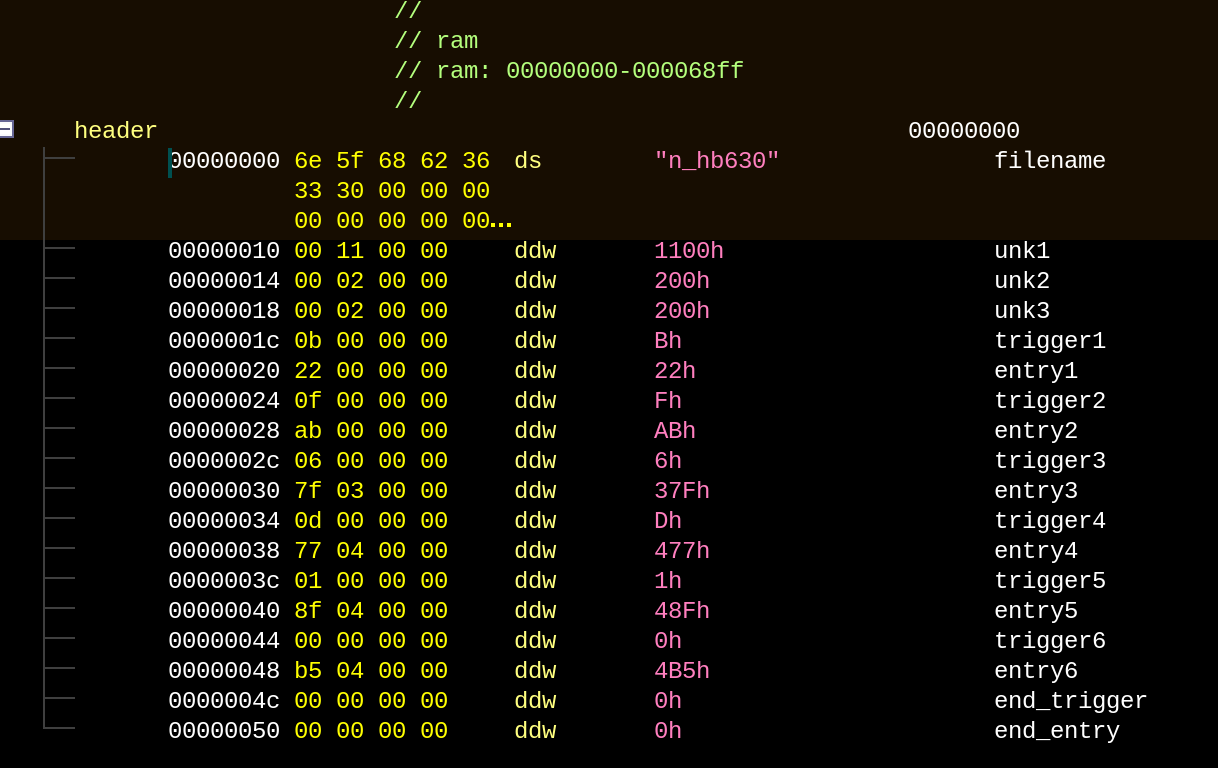
Sephiroth AI header labelled
Analyzer
I talked earlier about how Ghidra’s design around analyzers is one big positive point to me, so I guess I gotta explain myself, huh? Ghidra’s analysis is designed around independent analyzers. Each analyzer has a very specific task, such as finding constant propagation or studying control flow. What makes the analyzer design of Ghidra so powerful is that you can chain together multiple ones and add to the defaults to get a better output. This is one of the reason Ghidra is called a Framework rather than a tool.
To show why this is useful, KH2 has an opcode, push.l, which pushes to the stack a pointer from a relocated value. This will be better with an example:
push.l s_event_00006728 00000a94 = "event"
push.v 0x3012c 00000a98
push.v 0xc7c 00000a9e
push.v 0x0 00000aa4
push.v 0x0 00000aaa
push.v 0x0 00000ab0
push.v 0x0 00000ab6
push.v 0x0 00000abc
push.v 0x0 00000ac2
push.v 0xc81 00000ac8
push.v 0x0 00000ace
syscall 0x1,0x6 00000ad4In this case push.l, at the binary level, does not store the pointer to event,
but stores the value 0x10-(addr»1). As KH2 AI operations are aligned every 2
bytes this makes sense and allows to save up one bit, even though the address
space is so small that it serves absolutely no use.
The funny thing is that some syscalls take function pointers as arguments, and
those can be NULL. To avoid this case KH2 does store them as raw values and use
the push.v opcode to push them, to avoid relocation being applied to 0x0. This
is great for them as it allows to pass a NULL value easily to a syscall but less so for us as
it makes analyzing the program harder, since Ghidra cannot identify random
values and execute a relocation algorithm on all of them just to find a correct
address. Even if you expanded it to do so it would break the analysis anyways
since every value is not a function pointer.
Without finding those functions, we are at 74 functions analyzed for Sephiroth’s
AI, which is ok I guess? But we can make it better, as shown below:
push.ap r1,0xf0 00000a90
push.l s_event_00006728 00000a94 = "event"
push.v 0x3012c 00000a98
push.v 0xc7c 00000a9e pointer to: 1908
push.v 0x0 00000aa4
push.v 0x0 00000aaa
push.v 0x0 00000ab0
push.v 0x0 00000ab6
push.v 0x0 00000abc
push.v 0x0 00000ac2
push.v 0xc81 00000ac8 pointer to: 1912
push.v 0x0 00000ace
syscall 0x1,0x6 00000ad4Long story short I wrote an analyzer that scans for arguments of specific syscalls(in our case the syscall 1,6) and scans the non-NULL function pointers arguments in order to discover new functions. Long story short in order not to break the assembler I decided to put the function address as automatically generated comments and after the analyzer is done executing, to execute another analyzing pass if it found any new functions. This brings up the number of analyzed functions to 365 which is already much better!
Release
Now that I’ve highlighted the important part of my work, I can say with great pleasure that ghidra-kh2ai v0.1, along with KH2AI ISA v0.1 are released at this address!.
Please note that the processor specification still has some undocumented or partly documented instructions and that none of the syscalls are currently documented either. If you reversed anything new or found an errata please report it here so that I can add it into the next release.
You can find a video tutorial below explaining how to use the extension and Ghidra as a whole for people not knowing the software:
Conclusion
Now here’s the usual little talk: I was always wondering how much workload it was to reverse engineer a very specific and convoluted protocol, or other things I’ve worked on in the past, because most of the time I end up taking ten times more time than I should at work because of life. This time I was motivated and gave me a healthy five hours(with random breaks) work day, without weekends for a week. This limit was not only self-imposed due to actual time constraints(no, not christmas, what are you thinking, the CCC is more important!) but also not to stress myself too much about what I’ve finished or not and not to go too far into this rabbit hole, after all it’s just a week.
According to my git log I worked from Tue Dec 17 13:04:30 2019 +0100 to Mon Dec 23 15:15:48 2019 +0100, with semi random interruptions thourought the day. 6 days.
In 6 days I:
- reverse engineered the AI Parser of KH2.
- documented and reversed partly 53 instructions, fully 48, out of 68, a good 78%
- made up LaTeX classes and a manual that is about 70pages long.
- made an assembler, disassembler and decompiler thanks to the SLEIGH processor definition
- made two file loaders and one analyzer
- wrote this blog post
All in all a lot more than I expected I’d be able to produce in about 30hours, or less than a french work week! This shows how much of a big divide I can get between periodic hyperfocus and a standard work week. To be fairly honest, given a standard workplace environment and a 35hour regime, with little to no transport, I’d be nowhere near as fast as this most of the time. If anything, I’d say it’d be safe for me to assume I’d be around three to four times slower. I feel like I strive in an environment where I’m given freedom to actually do research like I want and not being forced to go to a desk each day too. That doesn’t mean I would like to live off researching KH, that’s a silly pasttime to me and I’m much more interested in more applicable things anyways.
This also means that this can be done in a fairly short amount of time! I never
wrote any SLEIGH definition nor java before this week and I was able to pick all
of it up on the fly.
While I am an experienced reverse engineer this definitely
shows that this kind of community work is totally possible given a competent
researcher/engineer. I am not going to say that no competent people of this
aspect is on such community but rather that the people trying the hardest should
maybe try to reevaluate their work. I have reversed something which has not
been reversed in any comprehensible fashion for now 10 years, on a very popular game with various AI mods.
I don’t want to sound like a know-it-all but it might be time to think about
changing your methodology.
Markus Gaasedelen from ret2 said that “There is no secret to hard-work” but I don’t believe that’s true, or at least the full story. You should always strive in a research environment to work smarter, not harder. I understand that the vulnerability research space is seeing a lot of pressure from exploiting security bugs in time, heck, I’m a vulnerability researcher myself but, personally, I think our entire methodology for finding security bugs is flawed. I am certain this can be more automated than that. After all look at Rust in the defense ground, when implemented correctly there is no memory corruption bugs possible anymore! Anyways all of this swap from RE to vuln research is just to say: try to see if your methodology can be improved, because it will always be possible, and sometimes it might make you so much better at a task that you’ll wonder how you lived without it. Yak shaving is never done for nothing! This applies to everything, from research methodology to tooling by passing through education. Do not try to be better, strive to be better.
And remember, merry Christmas!